As enterprises, large and small, accelerate their data modernization initiatives, it becomes imperative for cloud platforms like Azure to provide the breadth and depth of capabilities required for organizations to successfully execute.
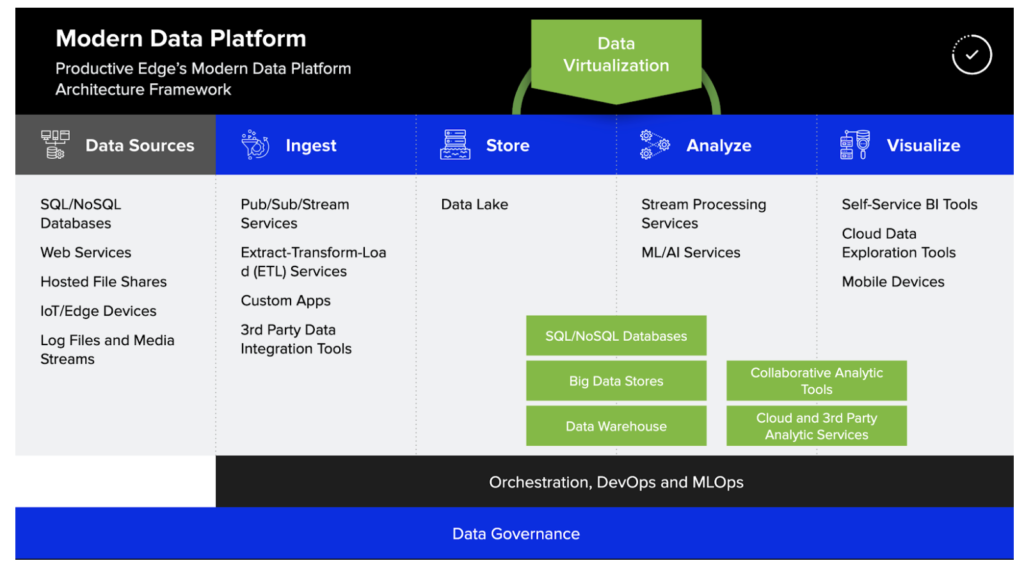
At Productive Edge, we have created a Modern Data Platform framework shown below that highlights the data and analytics workflow components needed to deliver a wide variety of analytics needs within the organization.
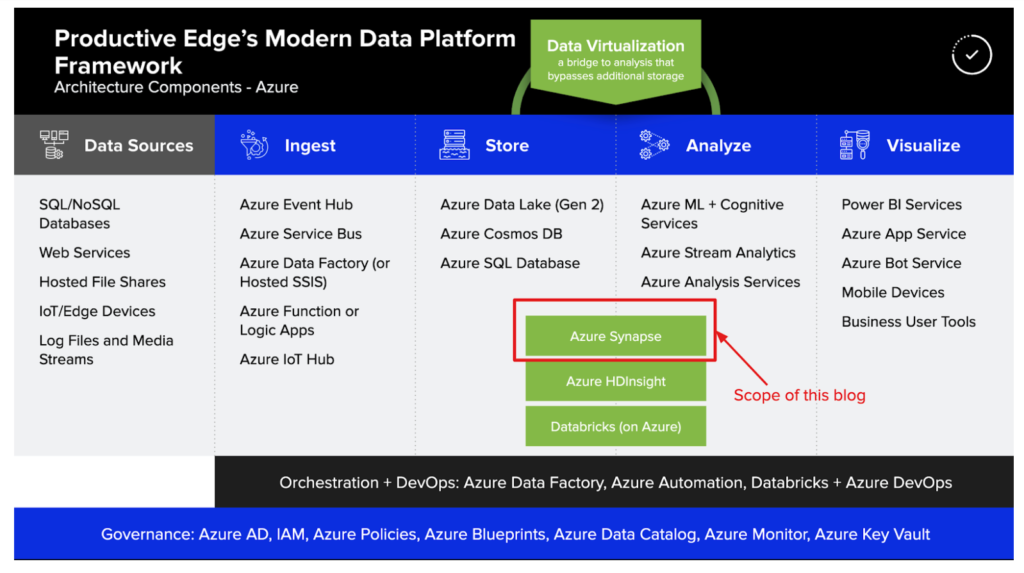
Over the past few years, Microsoft has been steadily adding data and analytics components in Azure and maturing each component to help you build and operationalize powerful and advanced analytics rapidly. In this blog, we will be exploring one of the newest offerings in Azure’s portfolio, Azure Synapse. Productive Edge’s Modern Data Platform framework has been updated below to show Microsoft offerings for each of the data and analytics workflow components along with where Azure Synapse fits.
What is Azure Synapse Analytics?
Azure Synapse Analytics is a rebranding of the Azure SQL Data Warehouse that aims to address much broader aspects of the analytics lifecycle. At its core, Synapse Analytics consolidates a number of Microsoft’s existing enterprise services under one banner, offering the flexibility of choices at each step of data storage, orchestration, and computation in one unified interface.
In doing so, Synapse Analytics alleviates the operational inefficiencies of isolated data silos that stem from using numerous systems across multiple platforms. Through the blending of the traditional data warehouse with big data analytics, Synapse Analytics enables users with complementary sets of skills to cooperate and capitalize on the best of both worlds. Synapse Analytics can directly access and process data from Azure SQL Data Warehouse, Azure Data Lake Store Gen2, Blob Storage, and Cosmos DB. Transferring big data across multiple systems comes with an inherent risk to data integrity. By consolidating multiple data storage into a single source of truth, Synapse Analytics ensures the consistency of the data throughout the analytics pipeline. Additionally, the availability of both structured and unstructured data in one system reduces the barrier to supplement analysis of one type of data with another.
Apache Spark Integration
Users can create and fully manage Spark pools within Synapse Analytics. The integration of Spark provides an effective solution for complex and large scale ETL scenarios. Spark enables handling of large data in-memory, resulting in much faster computation when compared to disk-based approaches. Spark pools ensure accessibility of data as they can be shut down or spun up without any loss of data. They are also designed to scale since adding and removing nodes as required can be automated.
The inclusion of other core components of Spark further empowers Synapse Analytics to establish cohesion across team members with different specializations. Implementing AI models on top of a data warehouse is streamlined thanks to the inclusion of Spark MLLib and Azure Machine Learning service. Spark also integrates with Spark SQL, Python, Scala, and .NET, adding flexibility to how Synapse Analytics can be used. Additionally, T-SQL used for querying SQL Data Warehouse can also be used to query spark data assets typically stored in Parquet. With the unified interface called Synapse Analytics Studio providing Jupyter-like notebooks for collaborative scripting, data engineers and data scientists who otherwise would be working in separate environments can easily combine their efforts to iterate through the process.
Azure Synapse Pushes Beyond Storage & Compute
In addition to data storage and computing, Synapse Analytics also provides data orchestration and reporting capabilities, becoming truly an end-to-end system. Integration with Azure Data Factory allows users to develop data transformation pipelines through a graphical interface called Data Flows.
Data Flows executions are scheduled and monitored through Data Factory. Data Factory employs Spark clusters to scale accordingly for large transformation tasks. For reporting, Synapse Analytics relies on Power BI as a self-service visualization tool. Business analysts will be able to generate visualizations and summary statistics directly from the data warehouse and machine learning models.
Synapse Analytics offers a serverless on-demand computing resource option along with the traditional provisioned ones. A way to make use of the new serverless setup is for initial testing to make informed decisions on the number of resources required for production. Serverless resources will be preferred for model fitting or data exploration jobs that tend to be unpredictable while provisioned workloads would be better suited for data warehousing tasks that occur more consistently.
Regardless of how the resources can be allocated, Synapse Analytics allows database administrators to manage and monitor all services in one place. Having fewer systems to manage can lead to the reduced total cost of ownership as it becomes easier to identify and shut down unused resources.
Choosing Between Azure Synapse and Azure Databricks
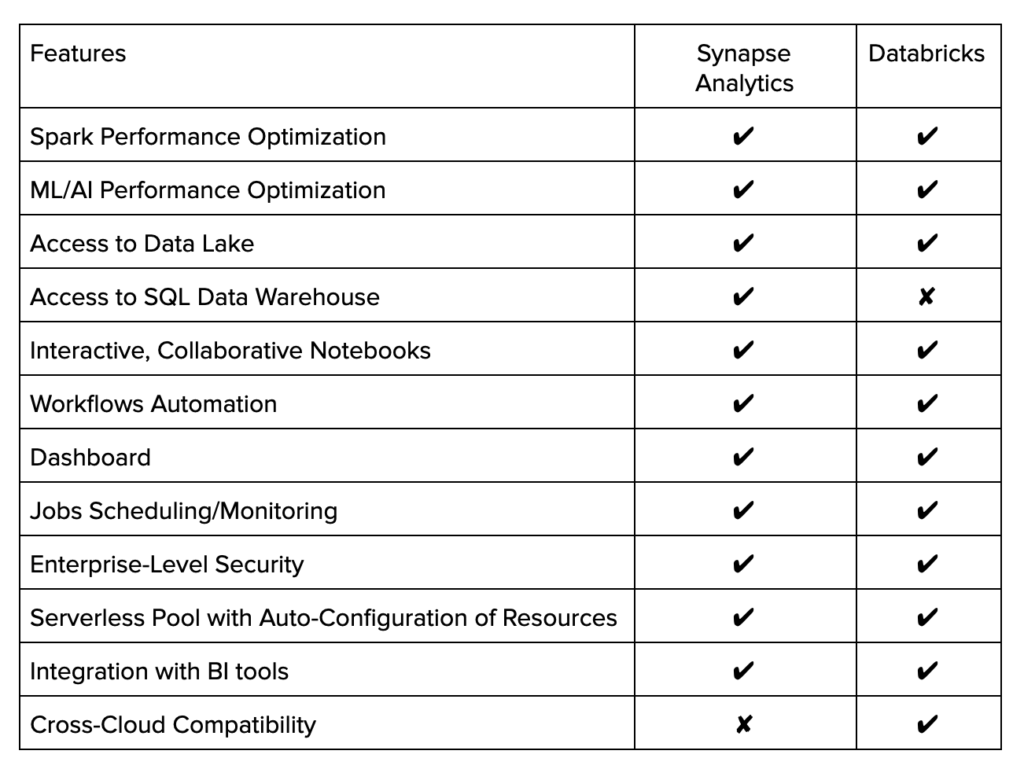
The choice between Azure Synapse Analytics and Azure Databricks comes down to whether or not the data warehousing process is required. There is a significant overlap in the services included in Databricks and Synapse Analytics. They both enable users to work with Apache Spark through providing performance optimization, notebook-style interactive workspace, security, and monitoring. One key difference is the lack of data warehouse management tools for Databricks. Although Databricks can use data from Blob storage through Azure Synapse connector, it still requires transferring large volumes of data. Through the integration with ASDW and multiple other data storage systems, Synapse Analytics enjoys a major benefit of built-in data warehouse integration.
Since the announcement back in Nov 2019, Azure Synapse Analytics workspace has been steadily rolling out its promised features in a public preview. With the exception of SQL Data Warehouse service that is fully functional, the rest of the services available in the preview should not be used for production as of yet.
Productive Edge's experts work with leading organizations to transform their digital business operations and elevate the customer experience. To learn more about how our technology consultants can help you deliver on your digital strategy, contact us today.